Reverse Engineering of VSCode Speech

Introduction
简单介绍一下起源哈,我最近在b站看到一个很有意思的STT工具
它可以将视频中的语音转换成文字,然后在视频中显示出来,关键效果很好
我就想到了它的原理,应该是Github Copilot Chat的语音识别功能
之后我就找了它的插件VsCode Speech
Embeded Speech Recognition
这是一个本地的嵌入式语音识别用到MircoSoft的Speech SDK
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import * as speech from "@vscode/node-speech";
const modelName = "<name of the speech model>";
const modelPath = "<path to the speech model>";
const modelKey = "<key for the speech model>";
// Live transcription from microphone
let transcriber = speech.createTranscriber(
{ modelName, modelPath, modelKey },
(err, res) => console.log(err, res)
);
// you can stop/start later
transcriber.stop();
transcriber.start();
// later when done...
transcriber.dispose();
|
Extension Source

基础目录是一个vscode 插件, 之后会包含其他语言的语言包
 核心就是这个
核心就是这个dist\main.js 里面包含了所有的逻辑代码
代码经过最小化和混淆, 但是还是可以通过一些手段还原出来,
大致就是用了一段加密获取model key, 然后调用了node-speech的接口,
可以看下这段代码
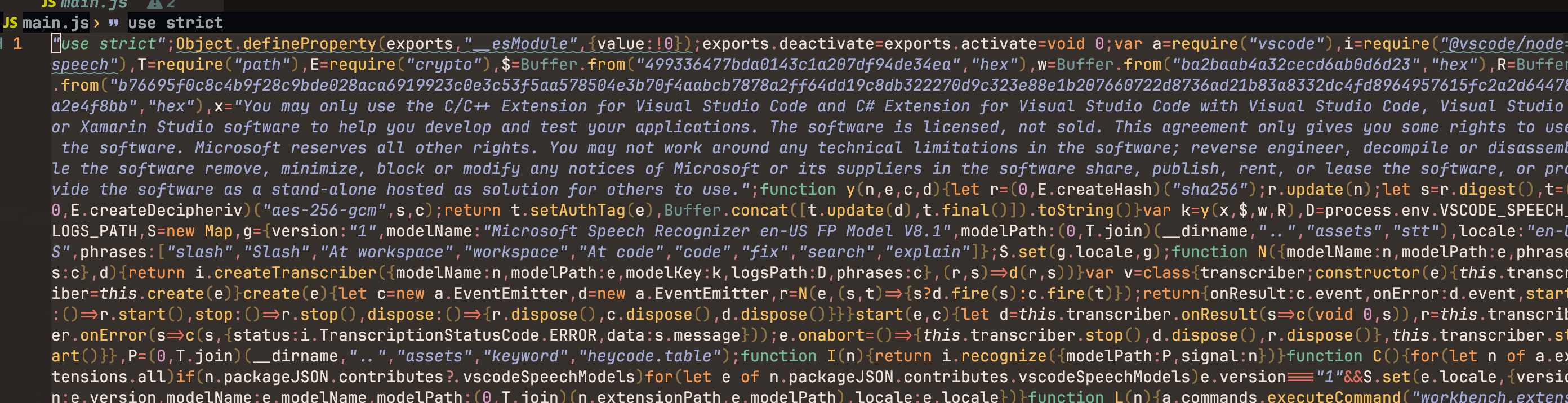
POC
Model key Get
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| //Generated by GPT-4-turbo
function decrypt(n, e, c, d) {
// n, e, c, and d are buffers
// create a sha256 hash
let hash = crypto.createHash('sha256');
// update the hash with the data in n
hash.update(n);
// digest the hash (i.e., finalize it and prevent further data from being added),
// producing a resultant buffer
let key = hash.digest();
// create a decipher object, specifying aes256 with a gcm mode of operation,
// use the key derived above and the provided IV
let decipher = crypto.createDecipheriv('aes-256-gcm', key, c);
// set the authentication tag to the provided one
decipher.setAuthTag(e);
// decrypt the provided encrypted data and finalize the decipher,
// converting the result to a string
// let decryptedText = Buffer.concat([decipher.update(d),decipher.final()]).toString();
let decryptedBuffer = Buffer.concat([decipher.update(d), decipher.final()]);
let decryptedText = decryptedBuffer.toString();
return decryptedText;
}
// you would use the function like this:
let decrypted = decrypt(x,end, w, r);
export { decrypted};
|
Speech Recognition
我还是一个ts新手, 所以我在AI辅助工具的帮助下,写了下面的识别代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| import { decrypted} from "./modelkey"
import path from "path"
import { createSynthesizer, TranscriptionStatusCode, ITranscriptionCallback, createTranscriber } from "@vscode/node-speech"
//uuid generate
import { v4 as uuidv4 } from 'uuid';
const modelName = "Microsoft Speech Recognizer zh-CN FP Model V3.1"
const modelPath = path.join(__dirname, "assets", "stt")
const modelKey = decrypted;
export function wrapperTranscriberCallback(session_id: string, callback: ITranscriptionCallback): ITranscriptionCallback {
return (error, result) => {
let resData = result.data ? result.data : "";
const t = session_id ? session_id : "";
if (error) {
console.error(`[speech-${t}] error: ${error.message}`);
callback(error, result);
} else {
switch(result.status) {
case TranscriptionStatusCode.STARTED:
console.log(`[speech-${t}] started speech-to-text session${resData}`);
break;
case TranscriptionStatusCode.RECOGNIZING:
console.debug(`[speech-${t}] recognizing: ${resData}`);
break;
case TranscriptionStatusCode.RECOGNIZED:
console.log(`[speech-${t}] : ${resData}`);
break;
case TranscriptionStatusCode.NOT_RECOGNIZED:
console.debug(`[speech-${t}] not recognized${resData}`);
break;
case TranscriptionStatusCode.INITIAL_SILENCE_TIMEOUT:
console.debug(`[speech-${t}] initial silence timeout${resData}`);
break;
case TranscriptionStatusCode.END_SILENCE_TIMEOUT:
console.debug(`[speech-${t}] end silence timeout${resData}`);
break;
case TranscriptionStatusCode.SPEECH_START_DETECTED:
console.debug(`[speech-${t}] speech start detected${resData}`);
break;
case TranscriptionStatusCode.SPEECH_END_DETECTED:
console.debug(`[speech-${t}] speech end detected${resData}`);
break;
case TranscriptionStatusCode.STOPPED:
console.debug(`[speech-${t}] stopped speech-to-text session${resData}`);
break;
case TranscriptionStatusCode.DISPOSED:
console.debug(`[speech-${t}] disposed speech-to-text session${resData}`);
break;
case TranscriptionStatusCode.ERROR:
console.error(`[speech-${t}] error: ${resData}`);
break;
default:
console.log('Unknown transcription status:', result.status);
}
}}
}
use settimeout to simulate every 10 seconds to start a new session
setTimeout(() => {
const t = uuidv4();
const wrappedCallback = wrapperTranscriberCallback(t, (err, res) => console.log(err, res));
let transcriber = createTranscriber(
{ modelName, modelPath, modelKey },
wrappedCallback
);
transcriber.start();
}, 300);
|
Config
你需要将动态链接库放到对应的包目录下本地才会运行
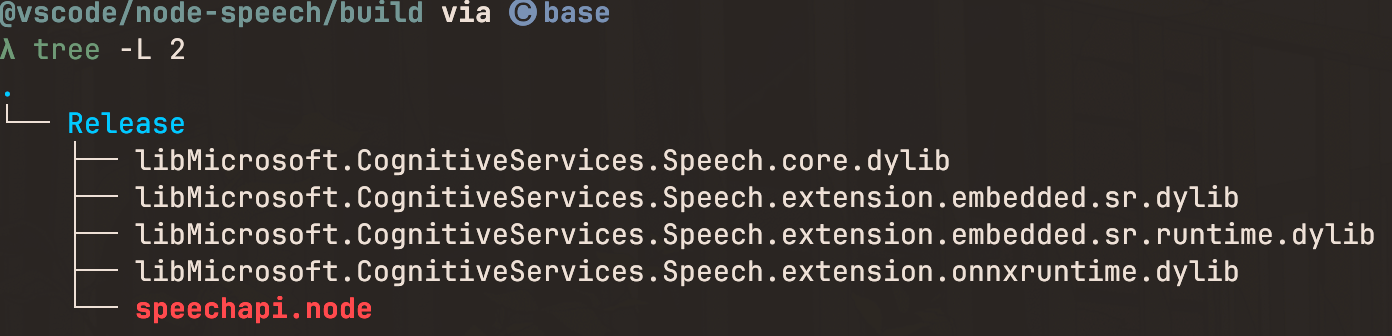 当然你也可以根据这个库的环境来自己编译打包,参考这个gyp文件
当然你也可以根据这个库的环境来自己编译打包,参考这个gyp文件
Usage

Summary
这次玩了一下vscode的语音识别插件, 通过逆向工程还原了一下它的代码,但其实它的RTF还是很好的,
缺点就是语音识别效果感觉不好, 没有达摩院的FunASR模型效果好,也主要是我测试的是中文,
达摩院的缺陷就是安装依赖很大至少3G,微软的这个很轻量,140M左右.
我看官方的SDK里面有提到TTS,未来也有可能有本地嵌入式的TTS模型,这个也是一个很好的方向,
不过这个STT暂时之支持C++/C#/Java的SDK,它是用onnxruntime来进行推理的
我们来看这个中文的语音模型里面有个很有意思的东西
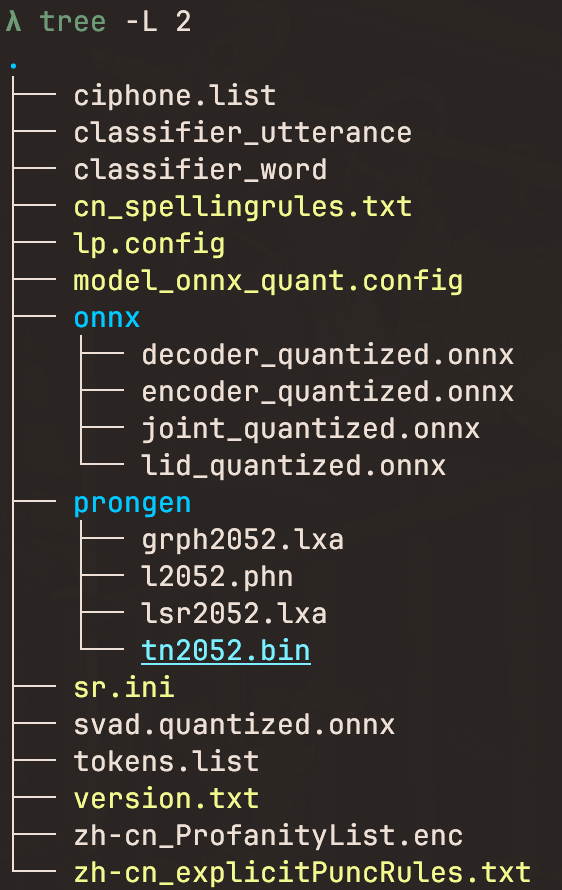
其实这个就是它的过滤词词表,但是我不知道如何解密它
还有一个很有意思的东西,有个keyword/heycode.table文件, 这个是服务于嵌入式语音识别的keyword recognition
Reference